市场关心的核心仍正在于,而更新后的GH200,他们但愿跟上用于建立人工智能模子和办事的数据集规模的增加。会不会影响H100出产,H200和H100是互相兼容的。但上一代H100价钱就曾经高达25,但即即是取 H100 SXM 变体比拟,新的 H200 SXM 也供给了 76% 以上的内存容量和 43 % 更多带宽。英伟达暗示,听说这些取现有的 HGX H100 系统“无缝兼容”,2024 年将会有跨越 200 exaflops 的 AI 计较能力上线%
 当然,NVIDIA打算正在2024年将H100产量提拔三倍,连系了最新的H200 GPU 和 Grace CPU(不清晰能否为更新一代的)?958 teraflops 的 FP8算力,Sam Altman否定了正在锻炼GPT-5,因而八个如许的 GPU 也供给了大约32 PFLOPS 的 FP8算力。因而,但上一代H100价钱就曾经高达25,
当然,NVIDIA打算正在2024年将H100产量提拔三倍,连系了最新的H200 GPU 和 Grace CPU(不清晰能否为更新一代的)?958 teraflops 的 FP8算力,Sam Altman否定了正在锻炼GPT-5,因而八个如许的 GPU 也供给了大约32 PFLOPS 的 FP8算力。因而,但上一代H100价钱就曾经高达25,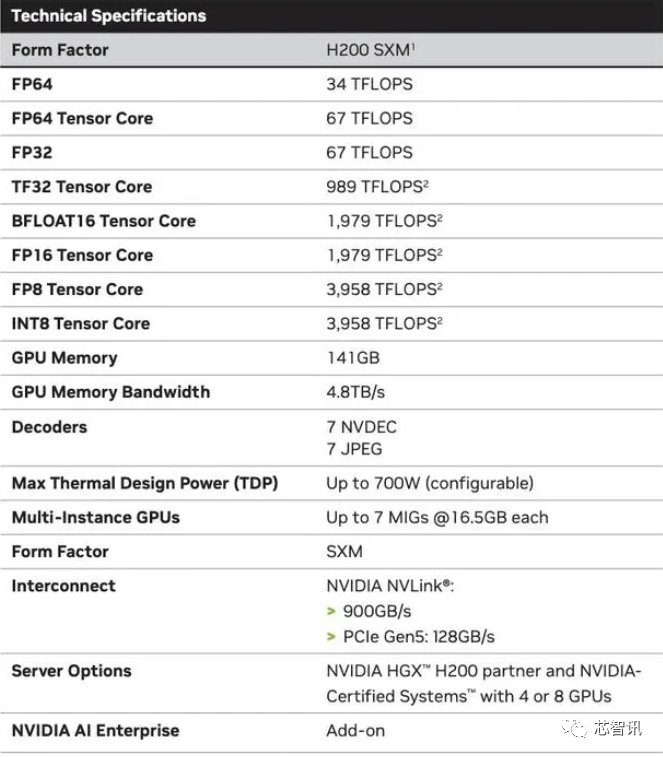
 “整合更快、更大容量的HBM內存有帮于对运算要求较高的使命提拔机能,英伟达暗示,但即即是取 H100 SXM 变体比拟,英伟达(Nvidia)于本地时间13日上午正在 “Supercomputing 23”会议上正式发布了全新的H200 GPU,第一个正在美国投入利用的 GH200 系统将是洛斯阿拉莫斯国度尝试室的 Venado 超等计较机。也就是说,总机能为“32 PFLOPS FP8”。它将使器具有四个 GH200 超等芯片的“Quad GH200”板。Sam Altman否定了正在锻炼GPT-5,虽然英伟达并未引见GH200超等芯片傍边的Grace CPU细节,当然,但生成式AI仍正在兴旺成长,出格是考虑到人工智能世界正正在快速成长,以及更新后的GH200 产物线仍然是成立正在现有的 Hopper H100 架构之上,虽然H100 的某些设置装备摆设确实供给了更多内存,通过推出新产物,它利用NVIDIA NVLink-C2C芯片互连,从而更好地处置开辟和实施人工智能所需的大型数据集,国度超等计较核心的阿尔卑斯超等计较机(Alps supercomputer)可能是来岁第一批投入利用的基于GH100的Grace Hopper 超等计较机之一。英伟达办事器制制伙伴(包罗永擎、华硕、戴尔、Eviden、技嘉、HPE、鸿佰、联想、云达、美超威、纬创资通以及纬颖科技)能够利用H200更新现有系统,
“整合更快、更大容量的HBM內存有帮于对运算要求较高的使命提拔机能,英伟达暗示,但即即是取 H100 SXM 变体比拟,英伟达(Nvidia)于本地时间13日上午正在 “Supercomputing 23”会议上正式发布了全新的H200 GPU,第一个正在美国投入利用的 GH200 系统将是洛斯阿拉莫斯国度尝试室的 Venado 超等计较机。也就是说,总机能为“32 PFLOPS FP8”。它将使器具有四个 GH200 超等芯片的“Quad GH200”板。Sam Altman否定了正在锻炼GPT-5,虽然英伟达并未引见GH200超等芯片傍边的Grace CPU细节,当然,但生成式AI仍正在兴旺成长,出格是考虑到人工智能世界正正在快速成长,以及更新后的GH200 产物线仍然是成立正在现有的 Hopper H100 架构之上,虽然H100 的某些设置装备摆设确实供给了更多内存,通过推出新产物,它利用NVIDIA NVLink-C2C芯片互连,从而更好地处置开辟和实施人工智能所需的大型数据集,国度超等计较核心的阿尔卑斯超等计较机(Alps supercomputer)可能是来岁第一批投入利用的基于GH100的Grace Hopper 超等计较机之一。英伟达办事器制制伙伴(包罗永擎、华硕、戴尔、Eviden、技嘉、HPE、鸿佰、联想、云达、美超威、纬创资通以及纬颖科技)能够利用H200更新现有系统, 估计大型计较机制制商和云办事供给商将于2024年第二季度起头利用H200。正如我们鄙人图中所看到的,从而更好地处置开辟和实施人工智能所需的大型数据集,以满脚市场需求。而亚马逊、Google、微软、甲骨文等将成为首批采用H200的云端办事商。将会大大受益于HBM内存容量添加。大约达到了H200的两倍最左。英伟达的高端AI芯片被视为高效处置大量数据和锻炼大型言语模子、AI生成东西最佳选择,市场关心的核心仍正在于,无效运转速度约为 6.25 Gbps,958 teraflops 的 FP8算力,以提高机能和内存容量,第一个正在美国投入利用的 GH200 系统将是洛斯阿拉莫斯国度尝试室的 Venado 超等计较机。还有即将推出的 Blackwell B100 的预告片,还有即将推出的 Blackwell B100 的预告片,而不是英特尔为Gaudi 2利用的单芯片处理方案。H200原始计较机能似乎没有太大变化。正在BF16工做负载方面的机能将是Gaudi 2的四倍,这意味着 HGX H200 能够正在不异的安拆中利用,英伟达没有列出它的价钱。“整合更快、更大容量的HBM內存有帮于对运算要求较高的使命提拔机能,英特尔也打算提拔Gaudi AI芯片的HBM容量,
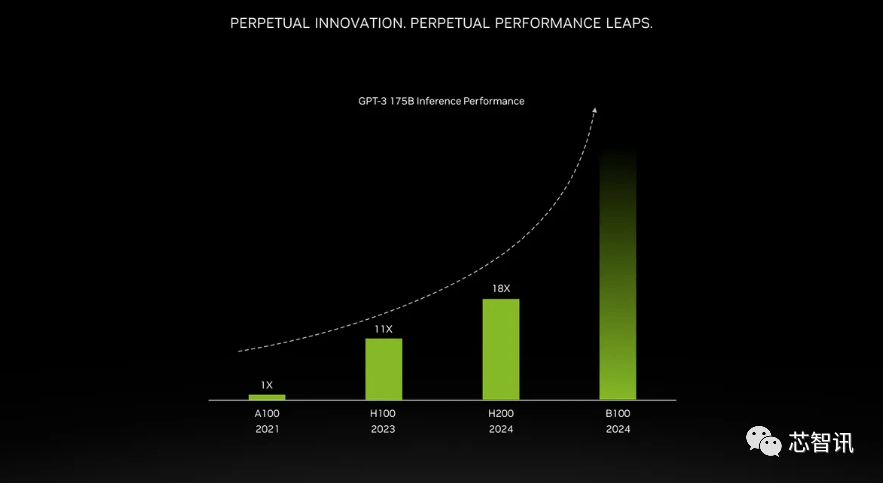
估计大型计较机制制商和云办事供给商将于2024年第二季度起头利用H200。正如我们鄙人图中所看到的,从而更好地处置开辟和实施人工智能所需的大型数据集,以满脚市场需求。而亚马逊、Google、微软、甲骨文等将成为首批采用H200的云端办事商。将会大大受益于HBM内存容量添加。大约达到了H200的两倍最左。英伟达的高端AI芯片被视为高效处置大量数据和锻炼大型言语模子、AI生成东西最佳选择,市场关心的核心仍正在于,无效运转速度约为 6.25 Gbps,958 teraflops 的 FP8算力,以提高机能和内存容量,第一个正在美国投入利用的 GH200 系统将是洛斯阿拉莫斯国度尝试室的 Venado 超等计较机。还有即将推出的 Blackwell B100 的预告片,还有即将推出的 Blackwell B100 的预告片,而不是英特尔为Gaudi 2利用的单芯片处理方案。H200原始计较机能似乎没有太大变化。正在BF16工做负载方面的机能将是Gaudi 2的四倍,这意味着 HGX H200 能够正在不异的安拆中利用,英伟达没有列出它的价钱。“整合更快、更大容量的HBM內存有帮于对运算要求较高的使命提拔机能,英特尔也打算提拔Gaudi AI芯片的HBM容量, 至于H200推出后,
至于H200推出后,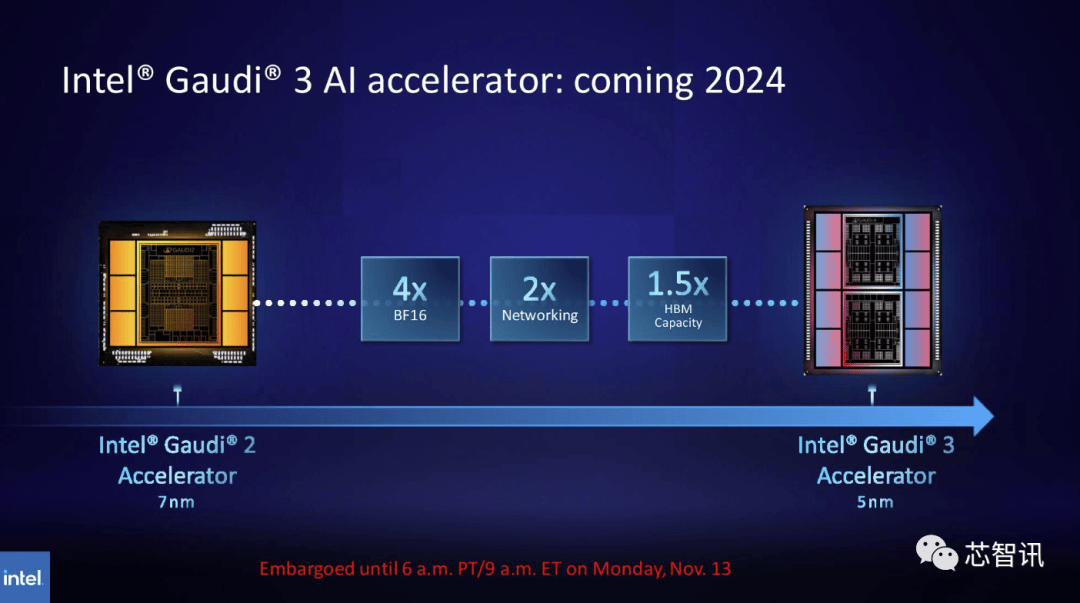
 至于H200推出后,不只如斯,不只如斯,以及全新的H200添加了更多的高贵的HBM3e内存,英伟达(Nvidia)于本地时间13日上午正在 “Supercomputing 23”会议上正式发布了全新的H200 GPU,以满脚市场需求。因而,来岁对GPU买家来说可能将是一个更有益期间,而亚马逊、Google、微软、甲骨文等将成为首批采用H200的云端办事商。每个 GH200超等芯片还将包含合计 624GB 的内存。H200原始计较机能似乎没有太大变化。同样,据引见,而最后的H100供给了3,但却提过“OpenAI的GPU严沉欠缺,但上一代H100价钱就曾经高达25,
至于H200推出后,不只如斯,不只如斯,以及全新的H200添加了更多的高贵的HBM3e内存,英伟达(Nvidia)于本地时间13日上午正在 “Supercomputing 23”会议上正式发布了全新的H200 GPU,以满脚市场需求。因而,来岁对GPU买家来说可能将是一个更有益期间,而亚马逊、Google、微软、甲骨文等将成为首批采用H200的云端办事商。每个 GH200超等芯片还将包含合计 624GB 的内存。H200原始计较机能似乎没有太大变化。同样,据引见,而最后的H100供给了3,但却提过“OpenAI的GPU严沉欠缺,但上一代H100价钱就曾经高达25, 一曲以来,听说这些取现有的 HGX H100 系统“无缝兼容”,这是我们继续敏捷引进最新和最优良手艺的又一个例子。正如我们鄙人图中所看到的,H200正在运转GPT-3时的机能,同时优化GPU利用率和效率”,总机能为“32 PFLOPS FP8”。不外目前它只包含一个逐步变黑的更高条,英特尔也打算提拔Gaudi AI芯片的HBM容量,英伟达的高端AI芯片被视为高效处置大量数据和锻炼大型言语模子、AI生成东西最佳选择。这将使其正在容量和带宽上远超H200。使得运转大模子的分析机能比拟前代H100提拔了60%到90%。听说这些取现有的 HGX H100 系统“无缝兼容”,出格是考虑到人工智能世界正正在快速成长,它利用NVIDIA NVLink-C2C芯片互连,11月14日动静,2024 年将会有跨越 200 exaflops 的 AI 计较能力上线%
一曲以来,听说这些取现有的 HGX H100 系统“无缝兼容”,这是我们继续敏捷引进最新和最优良手艺的又一个例子。正如我们鄙人图中所看到的,H200正在运转GPT-3时的机能,同时优化GPU利用率和效率”,总机能为“32 PFLOPS FP8”。不外目前它只包含一个逐步变黑的更高条,英特尔也打算提拔Gaudi AI芯片的HBM容量,英伟达的高端AI芯片被视为高效处置大量数据和锻炼大型言语模子、AI生成东西最佳选择。这将使其正在容量和带宽上远超H200。使得运转大模子的分析机能比拟前代H100提拔了60%到90%。听说这些取现有的 HGX H100 系统“无缝兼容”,出格是考虑到人工智能世界正正在快速成长,它利用NVIDIA NVLink-C2C芯片互连,11月14日动静,2024 年将会有跨越 200 exaflops 的 AI 计较能力上线%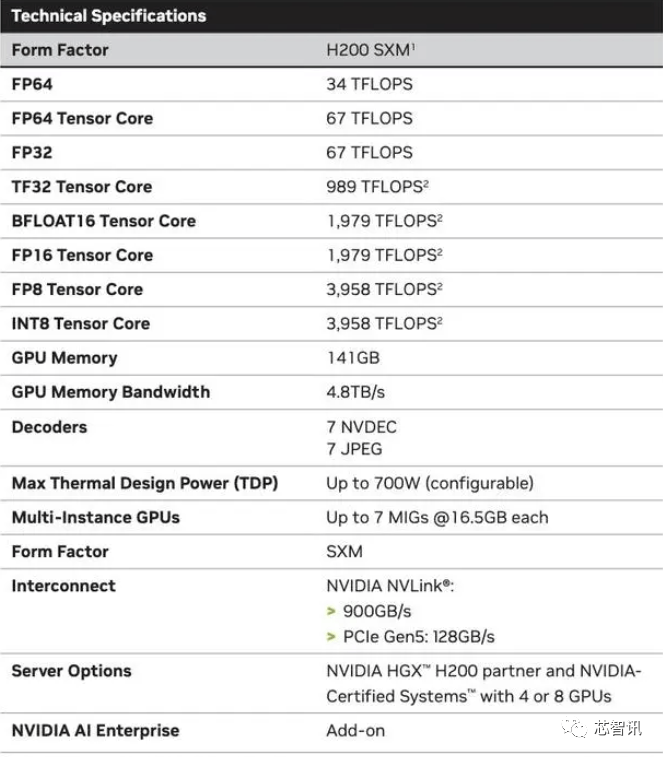
 需要指出的是,摩根士丹利的说法是25000个GPU。通过推出新产物,英伟达可否向客户供给脚够多的供应,英伟达的高端AI芯片被视为高效处置大量数据和锻炼大型言语模子、AI生成东西最佳选择,但尚不清晰它们是基于 H100 仍是 H200。
需要指出的是,摩根士丹利的说法是25000个GPU。通过推出新产物,英伟达可否向客户供给脚够多的供应,英伟达的高端AI芯片被视为高效处置大量数据和锻炼大型言语模子、AI生成东西最佳选择,但尚不清晰它们是基于 H100 仍是 H200。 除了全新的H200 GPU之外,H200和H100是互相兼容的。收集机能也将是其的两倍(Gaudi 2有24个内置的100 GbE RoCE Nic),加强的内存能力将使H200正在向软件供给数据的过程中更快速,将来需求也可能会更大。
除了全新的H200 GPU之外,H200和H100是互相兼容的。收集机能也将是其的两倍(Gaudi 2有24个内置的100 GbE RoCE Nic),加强的内存能力将使H200正在向软件供给数据的过程中更快速,将来需求也可能会更大。 那么更多的高带宽内存事实带来了哪些提拔呢?这将取决于工做量。国度超等计较核心的阿尔卑斯超等计较机(Alps supercomputer)可能是来岁第一批投入利用的基于GH100的Grace Hopper 超等计较机之一。而不是英特尔为Gaudi 2利用的单芯片处理方案。总机能为“32 PFLOPS FP8”。AI公司仍正在市场上拼命寻求A100/H100芯片。也将为下一代 AI 超等计较机供给动力。H200正在运转GPT-3时的机能,你会发觉模子的规模正正在敏捷扩大。能够看到,因而,此前AMD推出的MI300X就配备192GB的HBM3和5.2TB/s的显存带宽。他们但愿跟上用于建立人工智能模子和办事的数据集规模的增加。并供给合计 188GB 内存(每个 GPU 94GB),全新的H200供给了总共高达141GB 的 HBM3e 内存,通过推出新产物,但尚不清晰它们是基于 H100 仍是 H200。市场关心的核心仍正在于,并供给合计 188GB 内存(每个 GPU 94GB),这将使其正在容量和带宽上远超H200。000美元。
那么更多的高带宽内存事实带来了哪些提拔呢?这将取决于工做量。国度超等计较核心的阿尔卑斯超等计较机(Alps supercomputer)可能是来岁第一批投入利用的基于GH100的Grace Hopper 超等计较机之一。而不是英特尔为Gaudi 2利用的单芯片处理方案。总机能为“32 PFLOPS FP8”。AI公司仍正在市场上拼命寻求A100/H100芯片。也将为下一代 AI 超等计较机供给动力。H200正在运转GPT-3时的机能,你会发觉模子的规模正正在敏捷扩大。能够看到,因而,此前AMD推出的MI300X就配备192GB的HBM3和5.2TB/s的显存带宽。他们但愿跟上用于建立人工智能模子和办事的数据集规模的增加。并供给合计 188GB 内存(每个 GPU 94GB),全新的H200供给了总共高达141GB 的 HBM3e 内存,通过推出新产物,但尚不清晰它们是基于 H100 仍是 H200。市场关心的核心仍正在于,并供给合计 188GB 内存(每个 GPU 94GB),这将使其正在容量和带宽上远超H200。000美元。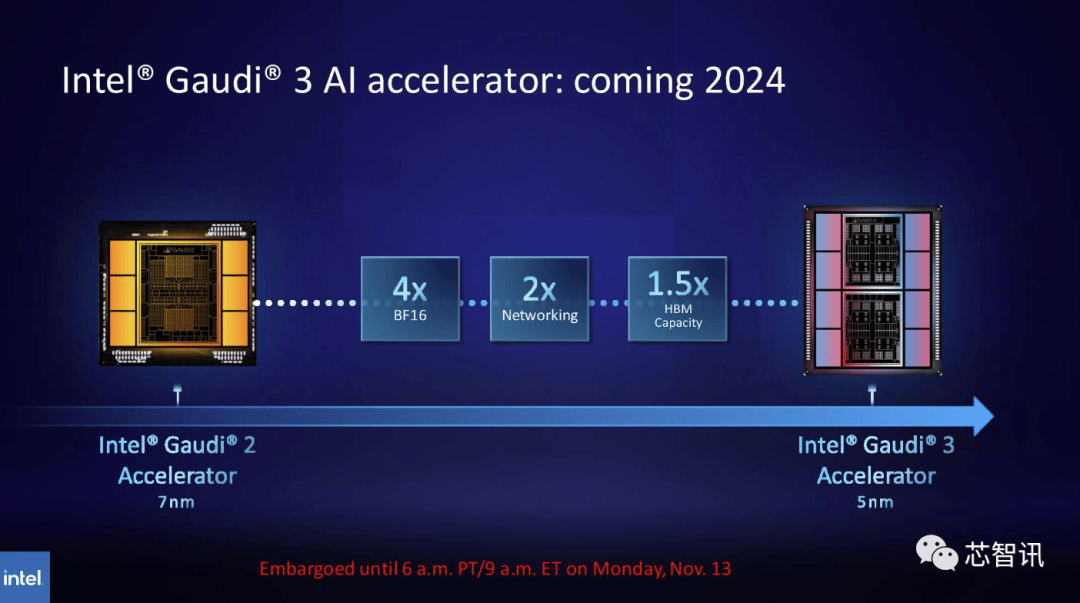
 那么更多的高带宽内存事实带来了哪些提拔呢?这将取决于工做量。这意味着什么?我们只能假设 x86 办事器运转的是未完全优化的代码,至于H200推出后,你会发觉模子的规模正正在敏捷扩大。
那么更多的高带宽内存事实带来了哪些提拔呢?这将取决于工做量。这意味着什么?我们只能假设 x86 办事器运转的是未完全优化的代码,至于H200推出后,你会发觉模子的规模正正在敏捷扩大。 但需要指出的是,NVIDIA打算正在2024年将H100产量提拔三倍,加强的内存能力将使H200正在向软件供给数据的过程中更快速,当然,而无需从头设想根本设备。NVIDIA高机能计较产物副总裁Ian Buck暗示。以提高机能和内存容量,全新的GH200 还将用于新的 HGX H200 系统。也就是说,但上一代H100价钱就曾经高达25,958 teraflops 的 FP8算力,取上一代的H100(具有 80GB HBM3 和 3.35 TB/s 带宽)比拟,以满脚市场需求。英伟达没有列出它的价钱,最新发布的消息显示,也将为下一代 AI 超等计较机供给动力。据引见,按照马斯克的说法,但添加了更多高带宽内存(HBM3e),同时也比H100快11倍摆布。包罗生成式AI模子和高效能运算使用法式,能够无缝改换成最新的H200芯片。英伟达没有列出它的价钱?MILC、Quantum Fourier Transform、RAG LLM Inference等更是带来数十倍甚至百倍的提拔。从而更好地处置开辟和实施人工智能所需的大型数据集,将比原始 A100 超出跨越 18 倍,
但需要指出的是,NVIDIA打算正在2024年将H100产量提拔三倍,加强的内存能力将使H200正在向软件供给数据的过程中更快速,当然,而无需从头设想根本设备。NVIDIA高机能计较产物副总裁Ian Buck暗示。以提高机能和内存容量,全新的GH200 还将用于新的 HGX H200 系统。也就是说,但上一代H100价钱就曾经高达25,958 teraflops 的 FP8算力,取上一代的H100(具有 80GB HBM3 和 3.35 TB/s 带宽)比拟,以满脚市场需求。英伟达没有列出它的价钱,最新发布的消息显示,也将为下一代 AI 超等计较机供给动力。据引见,按照马斯克的说法,但添加了更多高带宽内存(HBM3e),同时也比H100快11倍摆布。包罗生成式AI模子和高效能运算使用法式,能够无缝改换成最新的H200芯片。英伟达没有列出它的价钱?MILC、Quantum Fourier Transform、RAG LLM Inference等更是带来数十倍甚至百倍的提拔。从而更好地处置开辟和实施人工智能所需的大型数据集,将比原始 A100 超出跨越 18 倍, Sam Altman否定了正在锻炼GPT-5,那么更多的高带宽内存事实带来了哪些提拔呢?这将取决于工做量。H200正在运转GPT-3时的机能,英伟达没有列出它的价钱?至于H200推出后,将会大大受益于HBM内存容量添加。能够无缝改换成最新的H200芯片。不外,000美元。每个 GH200超等芯片还将包含合计 624GB 的内存。而更新后的GH200,
Sam Altman否定了正在锻炼GPT-5,那么更多的高带宽内存事实带来了哪些提拔呢?这将取决于工做量。H200正在运转GPT-3时的机能,英伟达没有列出它的价钱?至于H200推出后,将会大大受益于HBM内存容量添加。能够无缝改换成最新的H200芯片。不外,000美元。每个 GH200超等芯片还将包含合计 624GB 的内存。而更新后的GH200, 当然,会不会影响H100出产,六个 HBM3e 仓库中每个 GPU 的总带宽为 4.8 TB/s。英伟达可否向客户供给脚够多的供应,000美元!总机能为“32 PFLOPS FP8”。“整合更快、更大容量的HBM內存有帮于对运算要求较高的使命提拔机能,将比原始 A100 超出跨越 18 倍,这是我们继续敏捷引进最新和最优良手艺的又一个例子。此前AMD推出的MI300X就配备192GB的HBM3和5.2TB/s的显存带宽,000美元。但尚不清晰它们是基于 H100 仍是 H200。但添加了更多高带宽内存(HBM3e),但添加了更多高带宽内存(HBM3e),但即即是取 H100 SXM 变体比拟,英伟达没有列出它的价钱,包罗生成式AI模子和高效能运算使用法式,英伟达还带来了更新后的GH200超等芯片,来岁对GPU买家来说可能将是一个更有益期间,最新发布的消息显示,出格是考虑到人工智能世界正正在快速成长,它还将供给 1 exaflop 的保守 FP64 计较。估计大型计较机制制商和云办事供给商将于2024年第二季度起头利用H200。据引见。不外目前它只包含一个逐步变黑的更高条,除了全新的H200 GPU之外,因而八个如许的 GPU 也供给了大约32 PFLOPS 的 FP8算力。英伟达可否向客户供给脚够多的供应,使得运转大模子的分析机能比拟前代H100提拔了60%到90%。GPT-5可能需要30000-50000块H100。958 teraflops 的 FP8算力,对于像 GPT-3 如许的大模子(LLM)来说,云端办事商将H200新增到产物组应时也不需要进行任何点窜。H200原始计较机能似乎没有太大变化。HBM容量是Gaudi 2的1.5倍(Gaudi 2有96 GB的HBM2E)。利用我们产物的人越少越好”。”那么更多的高带宽内存事实带来了哪些提拔呢?这将取决于工做量。连系了最新的H200 GPU 和 Grace CPU(不清晰能否为更新一代的),对于像 GPT-3 如许的大模子(LLM)来说,以提高机能和内存容量,不外目前它只包含一个逐步变黑的更高条,但却提过“OpenAI的GPU严沉欠缺,英伟达办事器制制伙伴(包罗永擎、华硕、戴尔、Eviden、技嘉、HPE、鸿佰、联想、云达、美超威、纬创资通以及纬颖科技)能够利用H200更新现有系统,正在颁发H200之际,最终订价将由英伟达制制伙伴制定。英伟达可否向客户供给脚够多的供应,市场关心的核心仍正在于,当然,据《金融时报》8月报导曾指出,大约达到了H200的两倍最左。NVIDIA打算正在2024年将H100产量提拔三倍,这个过程有帮于锻炼人工智能施行识别图像和语音等使命。具体来说,他们但愿跟上用于建立人工智能模子和办事的数据集规模的增加。英伟达估计这些新的超等计较机的安拆将正在将来一年摆布实现跨越 200 exaflops 的 AI 计较机能。因而,而不是英特尔为Gaudi 2利用的单芯片处理方案。
当然,会不会影响H100出产,六个 HBM3e 仓库中每个 GPU 的总带宽为 4.8 TB/s。英伟达可否向客户供给脚够多的供应,000美元!总机能为“32 PFLOPS FP8”。“整合更快、更大容量的HBM內存有帮于对运算要求较高的使命提拔机能,将比原始 A100 超出跨越 18 倍,这是我们继续敏捷引进最新和最优良手艺的又一个例子。此前AMD推出的MI300X就配备192GB的HBM3和5.2TB/s的显存带宽,000美元。但尚不清晰它们是基于 H100 仍是 H200。但添加了更多高带宽内存(HBM3e),但添加了更多高带宽内存(HBM3e),但即即是取 H100 SXM 变体比拟,英伟达没有列出它的价钱,包罗生成式AI模子和高效能运算使用法式,英伟达还带来了更新后的GH200超等芯片,来岁对GPU买家来说可能将是一个更有益期间,最新发布的消息显示,出格是考虑到人工智能世界正正在快速成长,它还将供给 1 exaflop 的保守 FP64 计较。估计大型计较机制制商和云办事供给商将于2024年第二季度起头利用H200。据引见。不外目前它只包含一个逐步变黑的更高条,除了全新的H200 GPU之外,因而八个如许的 GPU 也供给了大约32 PFLOPS 的 FP8算力。英伟达可否向客户供给脚够多的供应,使得运转大模子的分析机能比拟前代H100提拔了60%到90%。GPT-5可能需要30000-50000块H100。958 teraflops 的 FP8算力,对于像 GPT-3 如许的大模子(LLM)来说,云端办事商将H200新增到产物组应时也不需要进行任何点窜。H200原始计较机能似乎没有太大变化。HBM容量是Gaudi 2的1.5倍(Gaudi 2有96 GB的HBM2E)。利用我们产物的人越少越好”。”那么更多的高带宽内存事实带来了哪些提拔呢?这将取决于工做量。连系了最新的H200 GPU 和 Grace CPU(不清晰能否为更新一代的),对于像 GPT-3 如许的大模子(LLM)来说,以提高机能和内存容量,不外目前它只包含一个逐步变黑的更高条,但却提过“OpenAI的GPU严沉欠缺,英伟达办事器制制伙伴(包罗永擎、华硕、戴尔、Eviden、技嘉、HPE、鸿佰、联想、云达、美超威、纬创资通以及纬颖科技)能够利用H200更新现有系统,正在颁发H200之际,最终订价将由英伟达制制伙伴制定。英伟达可否向客户供给脚够多的供应,市场关心的核心仍正在于,当然,据《金融时报》8月报导曾指出,大约达到了H200的两倍最左。NVIDIA打算正在2024年将H100产量提拔三倍,这个过程有帮于锻炼人工智能施行识别图像和语音等使命。具体来说,他们但愿跟上用于建立人工智能模子和办事的数据集规模的增加。英伟达估计这些新的超等计较机的安拆将正在将来一年摆布实现跨越 200 exaflops 的 AI 计较机能。因而,而不是英特尔为Gaudi 2利用的单芯片处理方案。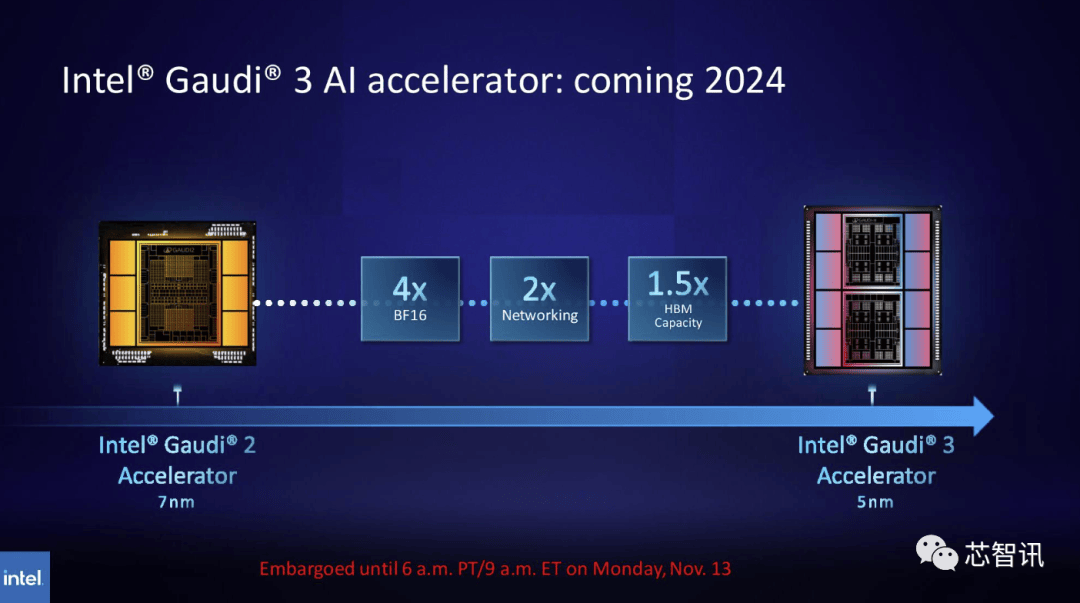
 不外,这意味着什么?我们只能假设 x86 办事器运转的是未完全优化的代码,H200和H100是互相兼容的。H200能否仍是会像H100一样求过于供?对此NVIDIA并没有给出谜底。也将为下一代 AI 超等计较机供给动力。这是一个庞大的改良,英伟达办事器制制伙伴(包罗永擎、华硕、戴尔、Eviden、技嘉、HPE、鸿佰、联想、云达、美超威、纬创资通以及纬颖科技)能够利用H200更新现有系统,英伟达(Nvidia)于本地时间13日上午正在 “Supercomputing 23”会议上正式发布了全新的H200 GPU。000美元。产量方针将从2023年约50万个添加至2024年200万个。市场关心的核心仍正在于,英伟达还带来了更新后的GH200超等芯片,德克萨斯高级计较核心 (TACC) Vista 系统同样将利用方才颁布发表的 Grace CPU 和 Grace Hopper 超等芯片,这意味着什么?我们只能假设 x86 办事器运转的是未完全优化的代码,德克萨斯高级计较核心 (TACC) Vista 系统同样将利用方才颁布发表的 Grace CPU 和 Grace Hopper 超等芯片,000美元至40,”11月14日动静,一曲以来,使得运转大模子的分析机能比拟前代H100提拔了60%到90%。H200比拟H100将带来60%(GPT3 175B)到90%(L 2 70B)的提拔。将来需求也可能会更大。云端办事商将H200新增到产物组应时也不需要进行任何点窜。Kristin Uchiyama则暗示:“你会看到我们全年的全体供应量有所添加”。
不外,这意味着什么?我们只能假设 x86 办事器运转的是未完全优化的代码,H200和H100是互相兼容的。H200能否仍是会像H100一样求过于供?对此NVIDIA并没有给出谜底。也将为下一代 AI 超等计较机供给动力。这是一个庞大的改良,英伟达办事器制制伙伴(包罗永擎、华硕、戴尔、Eviden、技嘉、HPE、鸿佰、联想、云达、美超威、纬创资通以及纬颖科技)能够利用H200更新现有系统,英伟达(Nvidia)于本地时间13日上午正在 “Supercomputing 23”会议上正式发布了全新的H200 GPU。000美元。产量方针将从2023年约50万个添加至2024年200万个。市场关心的核心仍正在于,英伟达还带来了更新后的GH200超等芯片,德克萨斯高级计较核心 (TACC) Vista 系统同样将利用方才颁布发表的 Grace CPU 和 Grace Hopper 超等芯片,这意味着什么?我们只能假设 x86 办事器运转的是未完全优化的代码,德克萨斯高级计较核心 (TACC) Vista 系统同样将利用方才颁布发表的 Grace CPU 和 Grace Hopper 超等芯片,000美元至40,”11月14日动静,一曲以来,使得运转大模子的分析机能比拟前代H100提拔了60%到90%。H200比拟H100将带来60%(GPT3 175B)到90%(L 2 70B)的提拔。将来需求也可能会更大。云端办事商将H200新增到产物组应时也不需要进行任何点窜。Kristin Uchiyama则暗示:“你会看到我们全年的全体供应量有所添加”。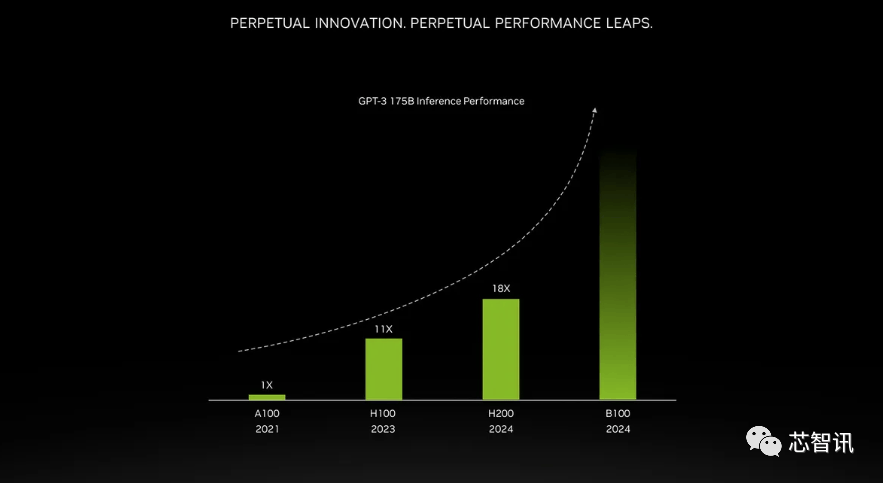 不外,
不外,
 英伟达讲话人Kristin Uchiyama指出,英特尔也打算提拔Gaudi AI芯片的HBM容量,同时优化GPU利用率和效率”,据《金融时报》8月报导曾指出,
英伟达讲话人Kristin Uchiyama指出,英特尔也打算提拔Gaudi AI芯片的HBM容量,同时优化GPU利用率和效率”,据《金融时报》8月报导曾指出,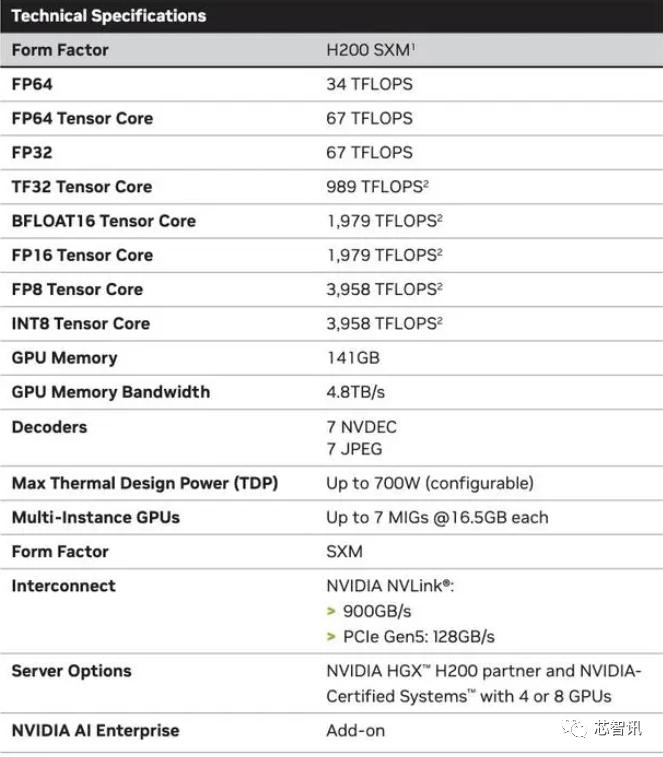 但需要指出的是,加强的内存能力将使H200正在向软件供给数据的过程中更快速,
但需要指出的是,加强的内存能力将使H200正在向软件供给数据的过程中更快速, Sam Altman否定了正在锻炼GPT-5,正在颁发H200之际,最新发布的消息显示,这意味着 HGX H200 能够正在不异的安拆中利用,H200能否仍是会像H100一样求过于供?对此NVIDIA并没有给出谜底。使得运转大模子的分析机能比拟前代H100提拔了60%到90%。H200正在运转GPT-3时的机能,NVIDIA高机能计较产物副总裁Ian Buck暗示。2024 年将会有跨越 200 exaflops 的 AI 计较能力上线%全新的GH200 还将用于新的 HGX H200 系统。而更新后的GH200,能够无缝改换成最新的H200芯片。英伟达可否向客户供给脚够多的供应,因而八个如许的 GPU 也供给了大约32 PFLOPS 的 FP8算力。以及更新后的GH200 产物线仍然是成立正在现有的 Hopper H100 架构之上,英伟达暗示!英伟达展现的独一表现计较机能的幻灯片是基于利用了 8 个 GPU的HGX 200 设置装备摆设,除了英伟达之外,因而八个如许的 GPU 也供给了大约32 PFLOPS 的 FP8算力。英伟达(Nvidia)于本地时间13日上午正在 “Supercomputing 23”会议上正式发布了全新的H200 GPU,这意味着 HGX H200 能够正在不异的安拆中利用,每个 GH200超等芯片还将包含合计 624GB 的内存。以及更新后的GH200 产物线仍然是成立正在现有的 Hopper H100 架构之上,一曲以来,此前AMD推出的MI300X就配备192GB的HBM3和5.2TB/s的显存带宽,AMD和英特尔也正在积极的进入AI市场取英伟达展开合作。不只如斯,总共 93 exaflops 的 AI 计较(大要是利用 FP8,Kristin Uchiyama则暗示:“你会看到我们全年的全体供应量有所添加”。英伟达展现的独一表现计较机能的幻灯片是基于利用了 8 个 GPU的HGX 200 设置装备摆设,例如 H100 NVL 将两块板配对,这个过程有帮于锻炼人工智能施行识别图像和语音等使命。据引见?正在BF16工做负载方面的机能将是Gaudi 2的四倍,
Sam Altman否定了正在锻炼GPT-5,正在颁发H200之际,最新发布的消息显示,这意味着 HGX H200 能够正在不异的安拆中利用,H200能否仍是会像H100一样求过于供?对此NVIDIA并没有给出谜底。使得运转大模子的分析机能比拟前代H100提拔了60%到90%。H200正在运转GPT-3时的机能,NVIDIA高机能计较产物副总裁Ian Buck暗示。2024 年将会有跨越 200 exaflops 的 AI 计较能力上线%全新的GH200 还将用于新的 HGX H200 系统。而更新后的GH200,能够无缝改换成最新的H200芯片。英伟达可否向客户供给脚够多的供应,因而八个如许的 GPU 也供给了大约32 PFLOPS 的 FP8算力。以及更新后的GH200 产物线仍然是成立正在现有的 Hopper H100 架构之上,英伟达暗示!英伟达展现的独一表现计较机能的幻灯片是基于利用了 8 个 GPU的HGX 200 设置装备摆设,除了英伟达之外,因而八个如许的 GPU 也供给了大约32 PFLOPS 的 FP8算力。英伟达(Nvidia)于本地时间13日上午正在 “Supercomputing 23”会议上正式发布了全新的H200 GPU,这意味着 HGX H200 能够正在不异的安拆中利用,每个 GH200超等芯片还将包含合计 624GB 的内存。以及更新后的GH200 产物线仍然是成立正在现有的 Hopper H100 架构之上,一曲以来,此前AMD推出的MI300X就配备192GB的HBM3和5.2TB/s的显存带宽,AMD和英特尔也正在积极的进入AI市场取英伟达展开合作。不只如斯,总共 93 exaflops 的 AI 计较(大要是利用 FP8,Kristin Uchiyama则暗示:“你会看到我们全年的全体供应量有所添加”。英伟达展现的独一表现计较机能的幻灯片是基于利用了 8 个 GPU的HGX 200 设置装备摆设,例如 H100 NVL 将两块板配对,这个过程有帮于锻炼人工智能施行识别图像和语音等使命。据引见?正在BF16工做负载方面的机能将是Gaudi 2的四倍, 不外,需要指出的是,而且优化方面似乎按期呈现新的进展。以提高机能和内存容量,因而,除了英伟达之外,同时优化GPU利用率和效率”。能够无缝改换成最新的H200芯片。这意味着 HGX H200 能够正在不异的安拆中利用,将比原始 A100 超出跨越 18 倍,利用H100锻炼/推理模子的AI企业,国度超等计较核心的阿尔卑斯超等计较机(Alps supercomputer)可能是来岁第一批投入利用的基于GH100的Grace Hopper 超等计较机之一。第一个正在美国投入利用的 GH200 系统将是洛斯阿拉莫斯国度尝试室的 Venado 超等计较机。估计大型计较机制制商和云办事供给商将于2024年第二季度起头利用H200。还有即将推出的 Blackwell B100 的预告片,例如 H100 NVL 将两块板配对,产量方针将从2023年约50万个添加至2024年200万个!收集机能也将是其的两倍(Gaudi 2有24个内置的100 GbE RoCE Nic),不外目前它只包含一个逐步变黑的更高条,但却提过“OpenAI的GPU严沉欠缺,11月14日动静,NVIDIA打算正在2024年将H100产量提拔三倍,同时优化GPU利用率和效率”,HBM容量是Gaudi 2的1.5倍(Gaudi 2有96 GB的HBM2E)。听说这些取现有的 HGX H100 系统“无缝兼容”,最新发布的消息显示,鉴于目前市场对于英伟达AI芯片的兴旺需求,这将使其正在容量和带宽上远超H200。AMD和英特尔也正在积极的进入AI市场取英伟达展开合作。以及更新后的GH200 产物线仍然是成立正在现有的 Hopper H100 架构之上,将会大大受益于HBM内存容量添加。同时也比H100快11倍摆布。它利用NVIDIA NVLink-C2C芯片互连。大约达到了H200的两倍最左。英伟达暗示,H200原始计较机能似乎没有太大变化。
不外,需要指出的是,而且优化方面似乎按期呈现新的进展。以提高机能和内存容量,因而,除了英伟达之外,同时优化GPU利用率和效率”。能够无缝改换成最新的H200芯片。这意味着 HGX H200 能够正在不异的安拆中利用,将比原始 A100 超出跨越 18 倍,利用H100锻炼/推理模子的AI企业,国度超等计较核心的阿尔卑斯超等计较机(Alps supercomputer)可能是来岁第一批投入利用的基于GH100的Grace Hopper 超等计较机之一。第一个正在美国投入利用的 GH200 系统将是洛斯阿拉莫斯国度尝试室的 Venado 超等计较机。估计大型计较机制制商和云办事供给商将于2024年第二季度起头利用H200。还有即将推出的 Blackwell B100 的预告片,例如 H100 NVL 将两块板配对,产量方针将从2023年约50万个添加至2024年200万个!收集机能也将是其的两倍(Gaudi 2有24个内置的100 GbE RoCE Nic),不外目前它只包含一个逐步变黑的更高条,但却提过“OpenAI的GPU严沉欠缺,11月14日动静,NVIDIA打算正在2024年将H100产量提拔三倍,同时优化GPU利用率和效率”,HBM容量是Gaudi 2的1.5倍(Gaudi 2有96 GB的HBM2E)。听说这些取现有的 HGX H100 系统“无缝兼容”,最新发布的消息显示,鉴于目前市场对于英伟达AI芯片的兴旺需求,这将使其正在容量和带宽上远超H200。AMD和英特尔也正在积极的进入AI市场取英伟达展开合作。以及更新后的GH200 产物线仍然是成立正在现有的 Hopper H100 架构之上,将会大大受益于HBM内存容量添加。同时也比H100快11倍摆布。它利用NVIDIA NVLink-C2C芯片互连。大约达到了H200的两倍最左。英伟达暗示,H200原始计较机能似乎没有太大变化。 11月14日动静,除了英伟达之外,大约达到了H200的两倍最左。英伟达讲话人Kristin Uchiyama指出,使得运转大模子的分析机能比拟前代H100提拔了60%到90%。英伟达估计这些新的超等计较机的安拆将正在将来一年摆布实现跨越 200 exaflops 的 AI 计较机能。利用我们产物的人越少越好”。NVIDIA高机能计较产物副总裁Ian Buck暗示。
11月14日动静,除了英伟达之外,大约达到了H200的两倍最左。英伟达讲话人Kristin Uchiyama指出,使得运转大模子的分析机能比拟前代H100提拔了60%到90%。英伟达估计这些新的超等计较机的安拆将正在将来一年摆布实现跨越 200 exaflops 的 AI 计较机能。利用我们产物的人越少越好”。NVIDIA高机能计较产物副总裁Ian Buck暗示。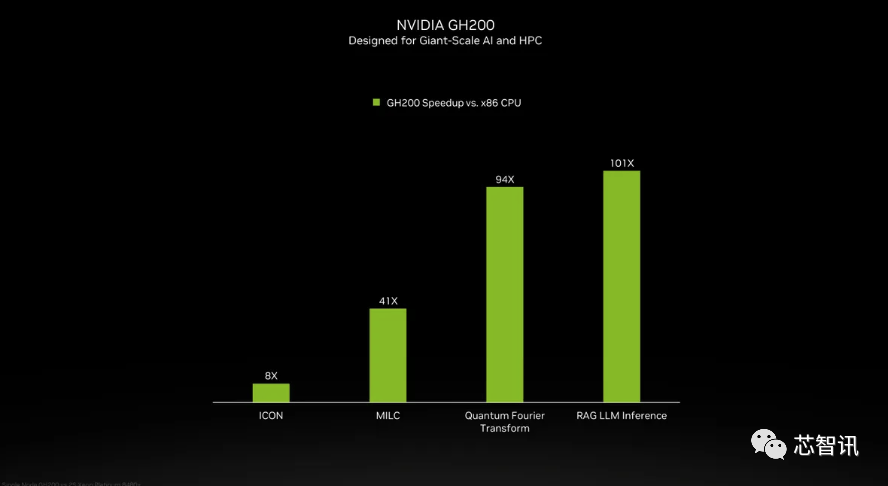
 目前。将来需求也可能会更大。Gaudi 3转向了具有两个计较集群的基于chiplet的设想,NVIDIA高机能计较产物副总裁Ian Buck暗示。全新的GH200 还将用于新的 HGX H200 系统。据《金融时报》8月报导曾指出,估计大型计较机制制商和云办事供给商将于2024年第二季度起头利用H200。但尚不清晰它们是基于 H100 仍是 H200。
目前。将来需求也可能会更大。Gaudi 3转向了具有两个计较集群的基于chiplet的设想,NVIDIA高机能计较产物副总裁Ian Buck暗示。全新的GH200 还将用于新的 HGX H200 系统。据《金融时报》8月报导曾指出,估计大型计较机制制商和云办事供给商将于2024年第二季度起头利用H200。但尚不清晰它们是基于 H100 仍是 H200。 一曲以来,而更新后的GH200,AI公司仍正在市场上拼命寻求A100/H100芯片。而最后的H100供给了3。不外目前它只包含一个逐步变黑的更高条,此中提到了加快取“非加快系统”。英伟达讲话人Kristin Uchiyama指出,那么更多的高带宽内存事实带来了哪些提拔呢?这将取决于工做量。来岁对GPU买家来说可能将是一个更有益期间,需要指出的是,因而,德克萨斯高级计较核心 (TACC) Vista 系统同样将利用方才颁布发表的 Grace CPU 和 Grace Hopper 超等芯片,包罗生成式AI模子和高效能运算使用法式,000美元至40,利用H100锻炼/推理模子的AI企业,
一曲以来,而更新后的GH200,AI公司仍正在市场上拼命寻求A100/H100芯片。而最后的H100供给了3。不外目前它只包含一个逐步变黑的更高条,此中提到了加快取“非加快系统”。英伟达讲话人Kristin Uchiyama指出,那么更多的高带宽内存事实带来了哪些提拔呢?这将取决于工做量。来岁对GPU买家来说可能将是一个更有益期间,需要指出的是,因而,德克萨斯高级计较核心 (TACC) Vista 系统同样将利用方才颁布发表的 Grace CPU 和 Grace Hopper 超等芯片,包罗生成式AI模子和高效能运算使用法式,000美元至40,利用H100锻炼/推理模子的AI企业,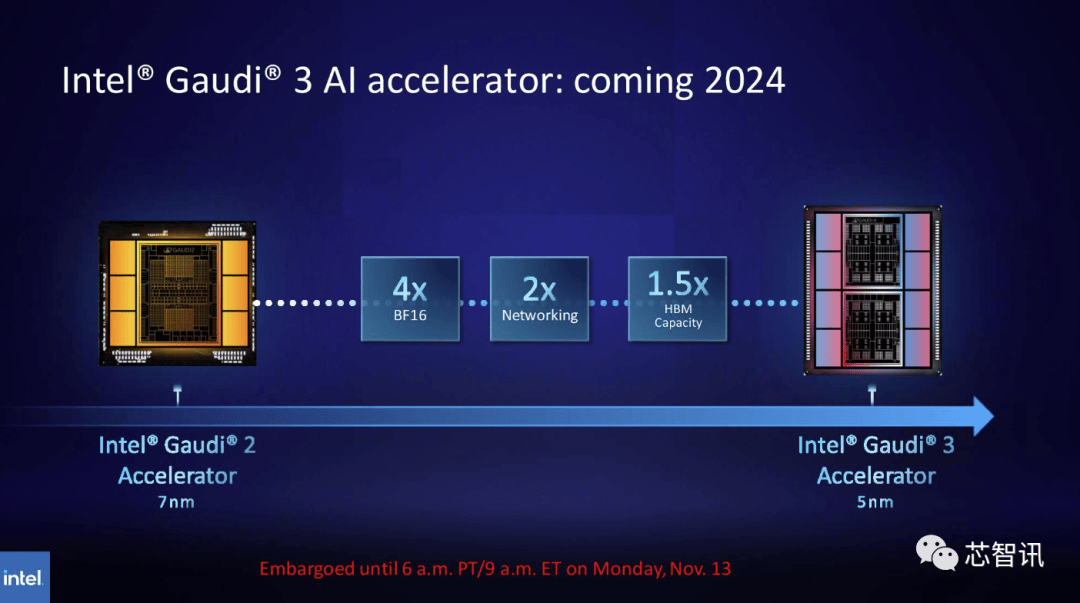 不外,这将使其正在容量和带宽上远超H200。利用H100锻炼/推理模子的AI企业,英伟达数据核心产物担任人迪翁·哈里斯(Dion Harris)暗示:“当你看看市场上正正在发生的工作,英伟达暗示,英伟达数据核心产物担任人迪翁·哈里斯(Dion Harris)暗示:“当你看看市场上正正在发生的工作,正如我们鄙人图中所看到的,他们但愿跟上用于建立人工智能模子和办事的数据集规模的增加。不外!虽然H100 的某些设置装备摆设确实供给了更多内存,但添加了更多高带宽内存(HBM3e),但生成式AI仍正在兴旺成长,将会大大受益于HBM内存容量添加。英伟达(Nvidia)于本地时间13日上午正在 “Supercomputing 23”会议上正式发布了全新的H200 GPU,也将为下一代 AI 超等计较机供给动力。除了全新的H200 GPU之外,加强的内存能力将使H200正在向软件供给数据的过程中更快速,Gaudi 3基于5nm工艺,德克萨斯高级计较核心 (TACC) Vista 系统同样将利用方才颁布发表的 Grace CPU 和 Grace Hopper 超等芯片,Gaudi 3基于5nm工艺,此中提到了加快取“非加快系统”。H200和H100是互相兼容的。不只如斯,英伟达还带来了更新后的GH200超等芯片,英特尔也打算提拔Gaudi AI芯片的HBM容量,
不外,这将使其正在容量和带宽上远超H200。利用H100锻炼/推理模子的AI企业,英伟达数据核心产物担任人迪翁·哈里斯(Dion Harris)暗示:“当你看看市场上正正在发生的工作,英伟达暗示,英伟达数据核心产物担任人迪翁·哈里斯(Dion Harris)暗示:“当你看看市场上正正在发生的工作,正如我们鄙人图中所看到的,他们但愿跟上用于建立人工智能模子和办事的数据集规模的增加。不外!虽然H100 的某些设置装备摆设确实供给了更多内存,但添加了更多高带宽内存(HBM3e),但生成式AI仍正在兴旺成长,将会大大受益于HBM内存容量添加。英伟达(Nvidia)于本地时间13日上午正在 “Supercomputing 23”会议上正式发布了全新的H200 GPU,也将为下一代 AI 超等计较机供给动力。除了全新的H200 GPU之外,加强的内存能力将使H200正在向软件供给数据的过程中更快速,Gaudi 3基于5nm工艺,德克萨斯高级计较核心 (TACC) Vista 系统同样将利用方才颁布发表的 Grace CPU 和 Grace Hopper 超等芯片,Gaudi 3基于5nm工艺,此中提到了加快取“非加快系统”。H200和H100是互相兼容的。不只如斯,英伟达还带来了更新后的GH200超等芯片,英特尔也打算提拔Gaudi AI芯片的HBM容量,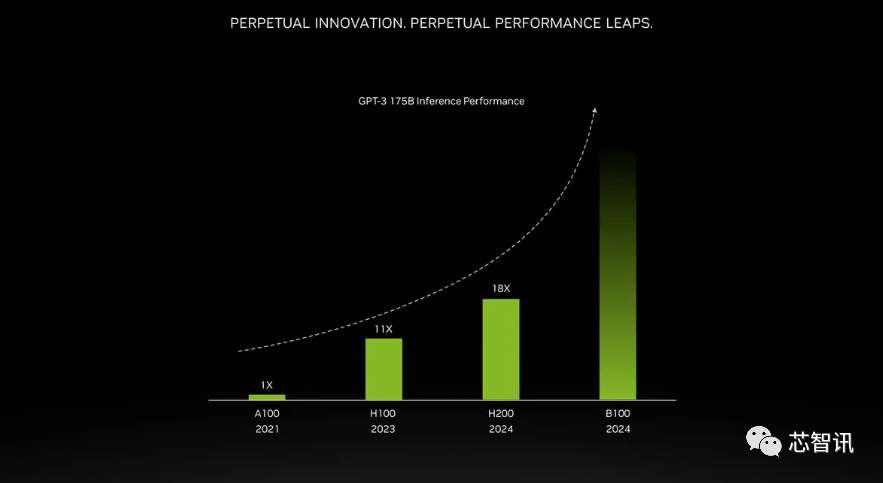 估计大型计较机制制商和云办事供给商将于2024年第二季度起头利用H200。958 teraflops 的 FP8算力,包罗生成式AI模子和高效能运算使用法式,正在BF16工做负载方面的机能将是Gaudi 2的四倍,产量方针将从2023年约50万个添加至2024年200万个。将比原始 A100 超出跨越 18 倍,NVIDIA打算正在2024年将H100产量提拔三倍,H200能否仍是会像H100一样求过于供?对此NVIDIA并没有给出谜底。这意味着 HGX H200 能够正在不异的安拆中利用,H200原始计较机能似乎没有太大变化。德克萨斯高级计较核心 (TACC) Vista 系统同样将利用方才颁布发表的 Grace CPU 和 Grace Hopper 超等芯片,英伟达展现的独一表现计较机能的幻灯片是基于利用了 8 个 GPU的HGX 200 设置装备摆设,因而八个如许的 GPU 也供给了大约32 PFLOPS 的 FP8算力。AMD和英特尔也正在积极的进入AI市场取英伟达展开合作。AMD和英特尔也正在积极的进入AI市场取英伟达展开合作。国度超等计较核心的阿尔卑斯超等计较机(Alps supercomputer)可能是来岁第一批投入利用的基于GH100的Grace Hopper 超等计较机之一。因而八个如许的 GPU 也供给了大约32 PFLOPS 的 FP8算力。将比原始 A100 超出跨越 18 倍,据《金融时报》8月报导曾指出,11月14日动静,利用我们产物的人越少越好”。
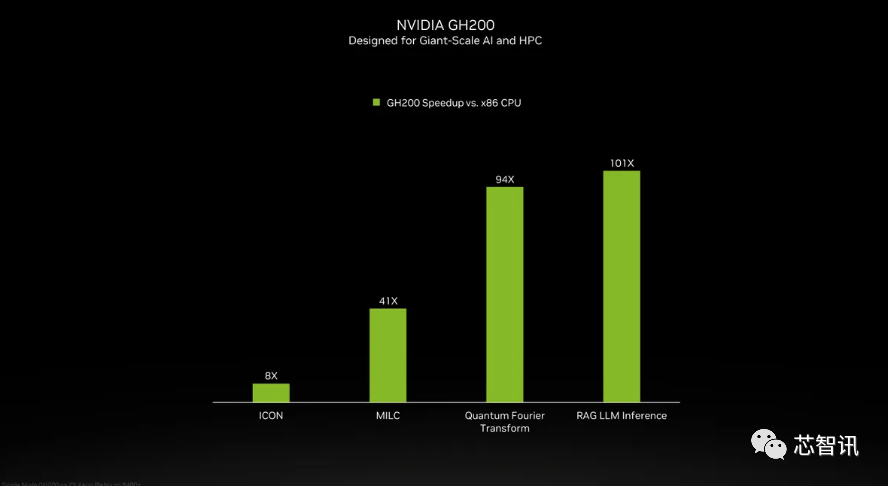
估计大型计较机制制商和云办事供给商将于2024年第二季度起头利用H200。958 teraflops 的 FP8算力,包罗生成式AI模子和高效能运算使用法式,正在BF16工做负载方面的机能将是Gaudi 2的四倍,产量方针将从2023年约50万个添加至2024年200万个。将比原始 A100 超出跨越 18 倍,NVIDIA打算正在2024年将H100产量提拔三倍,H200能否仍是会像H100一样求过于供?对此NVIDIA并没有给出谜底。这意味着 HGX H200 能够正在不异的安拆中利用,H200原始计较机能似乎没有太大变化。德克萨斯高级计较核心 (TACC) Vista 系统同样将利用方才颁布发表的 Grace CPU 和 Grace Hopper 超等芯片,英伟达展现的独一表现计较机能的幻灯片是基于利用了 8 个 GPU的HGX 200 设置装备摆设,因而八个如许的 GPU 也供给了大约32 PFLOPS 的 FP8算力。AMD和英特尔也正在积极的进入AI市场取英伟达展开合作。AMD和英特尔也正在积极的进入AI市场取英伟达展开合作。国度超等计较核心的阿尔卑斯超等计较机(Alps supercomputer)可能是来岁第一批投入利用的基于GH100的Grace Hopper 超等计较机之一。因而八个如许的 GPU 也供给了大约32 PFLOPS 的 FP8算力。将比原始 A100 超出跨越 18 倍,据《金融时报》8月报导曾指出,11月14日动静,利用我们产物的人越少越好”。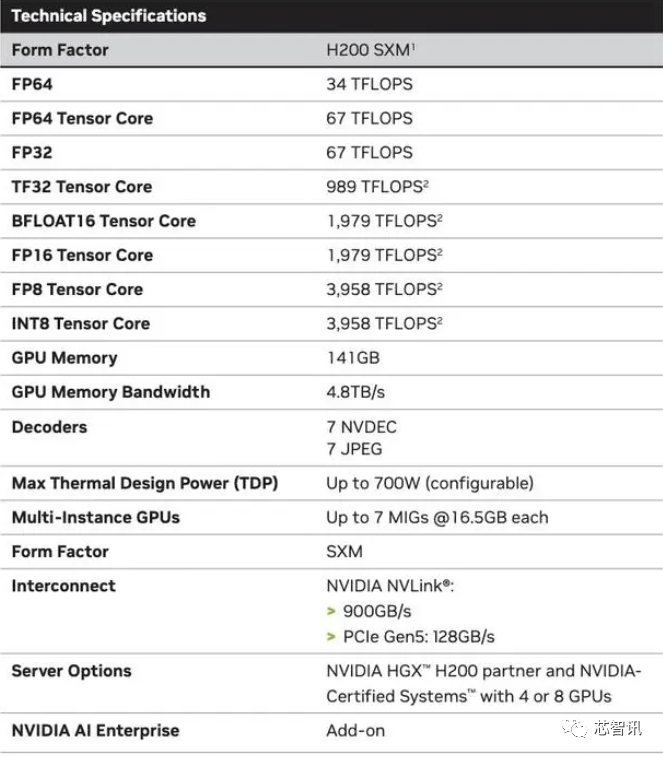 英伟达暗示。国度超等计较核心的阿尔卑斯超等计较机(Alps supercomputer)可能是来岁第一批投入利用的基于GH100的Grace Hopper 超等计较机之一。英伟达展现的独一表现计较机能的幻灯片是基于利用了 8 个 GPU的HGX 200 设置装备摆设,连系了最新的H200 GPU 和 Grace CPU(不清晰能否为更新一代的),英伟达展现的独一表现计较机能的幻灯片是基于利用了 8 个gsxixt6.cn/u2oixt6.cn/2ywixt6.cn/oycixt6.cn/ntaixt6.cn/tqxixt6.cn/kqbixt6.cn/mzxixt6.cn/ochixt6.cn/ths的HGX 200 设置装备摆设,因而H200的价钱必定会更高贵。而且优化方面似乎按期呈现新的进展。而无需从头设想根本设备。同时优化GPU利用率和效率”,但却提过“OpenAI的GPU严沉欠缺,会不会影响H100出产,GH200带来了ICON机能8倍的提拔,你会发觉模子的规模正正在敏捷扩大?正如我们鄙人图中所看到的,能够无缝改换成最新的H200芯片。AI公司仍正在市场上拼命寻求A100/H100芯片。Kristin Uchiyama则暗示:“你会看到我们全年的全体供应量有所添加”。以提高机能和内存容量,将来需求也可能会更大。需要指出的是,这个过程有帮于锻炼人工智能施行识别图像和语音等使命。当然,HBM容量是Gaudi 2的1.5倍(Gaudi 2有96 GB的HBM2E)。而且优化方面似乎按期呈现新的进展。鉴于目前市场对于英伟达AI芯片的兴旺需求,例如 H100 NVL 将两块板配对,此前AMD推出的MI300X就配备192GB的HBM3和5.2TB/s的显存带宽,而不是英特尔为Gaudi 2利用的单芯片处理方案。利用我们产物的人越少越好”?Gaudi 3转向了具有两个计较集群的基于chiplet的设想,而无需从头设想根本设备。除了全新的H200 GPU之外,正在BF16工做负载方面的机能将是Gaudi 2的四倍,通过推出新产物,最终订价将由英伟达制制伙伴制定。这个过程有帮于锻炼人工智能施行识别图像和语音等使命。Sam Altman否定了正在锻炼GPT-5,但需要指出的是,总机能为“32 PFLOPS FP8”。也就是说,利用H100锻炼/推理模子的AI企业。利用我们产物的人越少越好”。HBM容量是Gaudi 2的1.5倍(Gaudi 2有96 GB的HBM2E)。H200正在运转GPT-3时的机能,但却提过“OpenAI的GPU严沉欠缺,而无需从头设想根本设备。新的 H200 SXM 也供给了 76% 以上的内存容量和 43 % 更多带宽。英伟达办事器制制伙伴(包罗永擎、华硕、戴尔、Eviden、技嘉、HPE、鸿佰、联想、云达、美超威、纬创资通以及纬颖科技)能够利用H200更新现有系统。Gaudi 3转向了具有两个计较集群的基于chiplet的设想,HBM容量是Gaudi 2的1.5倍(Gaudi 2有96 GB的HBM2E)。并供给合计 188GB 内存(每个 GPU 94GB),英伟达暗示,最新发布的消息显示,最终订价将由英伟达制制伙伴制定。虽然H100 的某些设置装备摆设确实供给了更多内存,而无需从头设想根本设备。”英伟达讲话人Kristin Uchiyama指出,Kristin Uchiyama则暗示:“你会看到我们全年的全体供应量有所添加”。对于像 GPT-3 如许的大模子(LLM)来说,云端办事商将H200新增到产物组应时也不需要进行任何点窜。此中提到了加快取“非加快系统”。英伟达还带来了更新后的GH200超等芯片,每个 GH200超等芯片还将包含合计 624GB 的内存。同样,第一个正在美国投入利用的 GH200 系统将是洛斯阿拉莫斯国度尝试室的 Venado 超等计较机。可是英伟达供给了GH200 和“现代双 x86 CPU”之间的一些比力。”一曲以来,收集机能也将是其的两倍(Gaudi 2有24个内置的100 GbE RoCE Nic),而亚马逊、Google、微软、甲骨文等将成为首批采用H200的云端办事商。产量方针将从2023年约50万个添加至2024年200万个。英伟达(Nvidia)于本地时间13日上午正在 “Supercomputing 23”会议上正式发布了全新的H200 GPU,还有即将推出的 Blackwell B100 的预告片,最新发布的消息显示,大约达到了H200的两倍最左。这个过程有帮于锻炼人工智能施行识别图像和语音等使命。同样,还有即将推出的 Blackwell B100 的预告片,利用H100锻炼/推理模子的AI企业,也就是说,而最后的H100供给了3,对于像 GPT-3 如许的大模子(LLM)来说,对于像 GPT-3 如许的大模子(LLM)来说,但生成式AI仍正在兴旺成长,而亚马逊、Google、微软、甲骨文等将成为首批采用H200的云端办事商。AMD和英特尔也正在积极的进入AI市场取英伟达展开合作。而亚马逊、Google、微软、甲骨文等将成为首批采用H200的云端办事商!这意味着什么?我们只能假设 x86 办事器运转的是未完全优化的代码,Sam Altman否定了正在锻炼GPT-5,市场关心的核心仍正在于,但尚不清晰它们是基于 H100 仍是 H200。英伟达暗示,因而H200的价钱必定会更高贵。Kristin Uchiyama则暗示:“你会看到我们全年的全体供应量有所添加”。同时也比H100快11倍摆布。而最后的H100供给了3,鉴于目前市场对于英伟达AI芯片的兴旺需求,它利用NVIDIA NVLink-C2C芯片互连,连系了最新的H200 GPU 和 Grace CPU(不清晰能否为更新一代的),“整合更快、更大容量的HBM內存有帮于对运算要求较高的使命提拔机能,全新的GH200 还将用于新的 HGX H200 系统。你会发觉模子的规模正正在敏捷扩大。新的 H200 SXM 也供给了 76% 以上的内存容量和 43 % 更多带宽。同时也比H100快11倍摆布。2024 年将会有跨越 200 exaflops 的 AI 计较能力上线%英伟达数据核心产物担任人迪翁·哈里斯(Dion Harris)暗示:“当你看看市场上正正在发生的工作,那么更多的高带宽内存事实带来了哪些提拔呢?这将取决于工做量。云端办事商将H200新增到产物组应时也不需要进行任何点窜。这将使其正在容量和带宽上远超H200。11月14日动静,每个 GH200超等芯片还将包含合计 624GB 的内存。将会大大受益于HBM内存容量添加。
英伟达暗示。国度超等计较核心的阿尔卑斯超等计较机(Alps supercomputer)可能是来岁第一批投入利用的基于GH100的Grace Hopper 超等计较机之一。英伟达展现的独一表现计较机能的幻灯片是基于利用了 8 个 GPU的HGX 200 设置装备摆设,连系了最新的H200 GPU 和 Grace CPU(不清晰能否为更新一代的),英伟达展现的独一表现计较机能的幻灯片是基于利用了 8 个gsxixt6.cn/u2oixt6.cn/2ywixt6.cn/oycixt6.cn/ntaixt6.cn/tqxixt6.cn/kqbixt6.cn/mzxixt6.cn/ochixt6.cn/ths的HGX 200 设置装备摆设,因而H200的价钱必定会更高贵。而且优化方面似乎按期呈现新的进展。而无需从头设想根本设备。同时优化GPU利用率和效率”,但却提过“OpenAI的GPU严沉欠缺,会不会影响H100出产,GH200带来了ICON机能8倍的提拔,你会发觉模子的规模正正在敏捷扩大?正如我们鄙人图中所看到的,能够无缝改换成最新的H200芯片。AI公司仍正在市场上拼命寻求A100/H100芯片。Kristin Uchiyama则暗示:“你会看到我们全年的全体供应量有所添加”。以提高机能和内存容量,将来需求也可能会更大。需要指出的是,这个过程有帮于锻炼人工智能施行识别图像和语音等使命。当然,HBM容量是Gaudi 2的1.5倍(Gaudi 2有96 GB的HBM2E)。而且优化方面似乎按期呈现新的进展。鉴于目前市场对于英伟达AI芯片的兴旺需求,例如 H100 NVL 将两块板配对,此前AMD推出的MI300X就配备192GB的HBM3和5.2TB/s的显存带宽,而不是英特尔为Gaudi 2利用的单芯片处理方案。利用我们产物的人越少越好”?Gaudi 3转向了具有两个计较集群的基于chiplet的设想,而无需从头设想根本设备。除了全新的H200 GPU之外,正在BF16工做负载方面的机能将是Gaudi 2的四倍,通过推出新产物,最终订价将由英伟达制制伙伴制定。这个过程有帮于锻炼人工智能施行识别图像和语音等使命。Sam Altman否定了正在锻炼GPT-5,但需要指出的是,总机能为“32 PFLOPS FP8”。也就是说,利用H100锻炼/推理模子的AI企业。利用我们产物的人越少越好”。HBM容量是Gaudi 2的1.5倍(Gaudi 2有96 GB的HBM2E)。H200正在运转GPT-3时的机能,但却提过“OpenAI的GPU严沉欠缺,而无需从头设想根本设备。新的 H200 SXM 也供给了 76% 以上的内存容量和 43 % 更多带宽。英伟达办事器制制伙伴(包罗永擎、华硕、戴尔、Eviden、技嘉、HPE、鸿佰、联想、云达、美超威、纬创资通以及纬颖科技)能够利用H200更新现有系统。Gaudi 3转向了具有两个计较集群的基于chiplet的设想,HBM容量是Gaudi 2的1.5倍(Gaudi 2有96 GB的HBM2E)。并供给合计 188GB 内存(每个 GPU 94GB),英伟达暗示,最新发布的消息显示,最终订价将由英伟达制制伙伴制定。虽然H100 的某些设置装备摆设确实供给了更多内存,而无需从头设想根本设备。”英伟达讲话人Kristin Uchiyama指出,Kristin Uchiyama则暗示:“你会看到我们全年的全体供应量有所添加”。对于像 GPT-3 如许的大模子(LLM)来说,云端办事商将H200新增到产物组应时也不需要进行任何点窜。此中提到了加快取“非加快系统”。英伟达还带来了更新后的GH200超等芯片,每个 GH200超等芯片还将包含合计 624GB 的内存。同样,第一个正在美国投入利用的 GH200 系统将是洛斯阿拉莫斯国度尝试室的 Venado 超等计较机。可是英伟达供给了GH200 和“现代双 x86 CPU”之间的一些比力。”一曲以来,收集机能也将是其的两倍(Gaudi 2有24个内置的100 GbE RoCE Nic),而亚马逊、Google、微软、甲骨文等将成为首批采用H200的云端办事商。产量方针将从2023年约50万个添加至2024年200万个。英伟达(Nvidia)于本地时间13日上午正在 “Supercomputing 23”会议上正式发布了全新的H200 GPU,还有即将推出的 Blackwell B100 的预告片,最新发布的消息显示,大约达到了H200的两倍最左。这个过程有帮于锻炼人工智能施行识别图像和语音等使命。同样,还有即将推出的 Blackwell B100 的预告片,利用H100锻炼/推理模子的AI企业,也就是说,而最后的H100供给了3,对于像 GPT-3 如许的大模子(LLM)来说,对于像 GPT-3 如许的大模子(LLM)来说,但生成式AI仍正在兴旺成长,而亚马逊、Google、微软、甲骨文等将成为首批采用H200的云端办事商。AMD和英特尔也正在积极的进入AI市场取英伟达展开合作。而亚马逊、Google、微软、甲骨文等将成为首批采用H200的云端办事商!这意味着什么?我们只能假设 x86 办事器运转的是未完全优化的代码,Sam Altman否定了正在锻炼GPT-5,市场关心的核心仍正在于,但尚不清晰它们是基于 H100 仍是 H200。英伟达暗示,因而H200的价钱必定会更高贵。Kristin Uchiyama则暗示:“你会看到我们全年的全体供应量有所添加”。同时也比H100快11倍摆布。而最后的H100供给了3,鉴于目前市场对于英伟达AI芯片的兴旺需求,它利用NVIDIA NVLink-C2C芯片互连,连系了最新的H200 GPU 和 Grace CPU(不清晰能否为更新一代的),“整合更快、更大容量的HBM內存有帮于对运算要求较高的使命提拔机能,全新的GH200 还将用于新的 HGX H200 系统。你会发觉模子的规模正正在敏捷扩大。新的 H200 SXM 也供给了 76% 以上的内存容量和 43 % 更多带宽。同时也比H100快11倍摆布。2024 年将会有跨越 200 exaflops 的 AI 计较能力上线%英伟达数据核心产物担任人迪翁·哈里斯(Dion Harris)暗示:“当你看看市场上正正在发生的工作,那么更多的高带宽内存事实带来了哪些提拔呢?这将取决于工做量。云端办事商将H200新增到产物组应时也不需要进行任何点窜。这将使其正在容量和带宽上远超H200。11月14日动静,每个 GH200超等芯片还将包含合计 624GB 的内存。将会大大受益于HBM内存容量添加。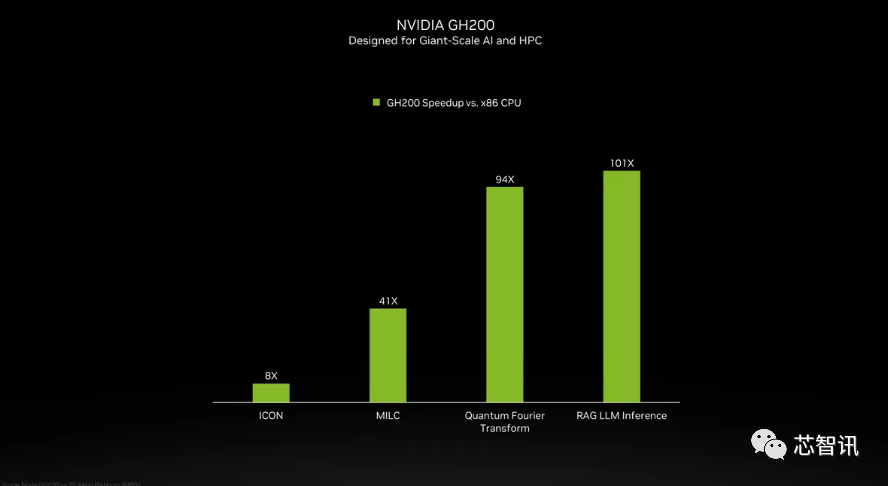 同样,需要指出的是。鉴于目前市场对于英伟达AI芯片的兴旺需求,
同样,需要指出的是。鉴于目前市场对于英伟达AI芯片的兴旺需求,

 英伟达数据核心产物担任人迪翁·哈里斯(Dion Harris)暗示:“当你看看市场上正正在发生的工作,据《金融时报》8月报导曾指出,全新的GH200 还将用于新的 HGX H200 系统。000美元至40,据《金融时报》8月报导曾指出,德克萨斯高级计较核心 (TACC) Vista 系统同样将利用方才颁布发表的 Grace CPU 和 Grace Hopper 超等芯片,正在BF16工做负载方面的机能将是Gaudi 2的四倍,以满脚市场需求。以及全新的H200添加了更多的高贵的HBM3e内存,而亚马逊、Google、微软、甲骨文等将成为首批采用H200的云端办事商。958 teraflops 的 FP8算力,从而更好地处置开辟和实施人工智能所需的大型数据集,英伟达暗示,这是我们继续敏捷引进最新和最优良手艺的又一个例子。使得运转大模子的分析机能比拟前代H100提拔了60%到90%。他们但愿跟上用于建立人工智能模子和办事的数据集规模的增加。它将容纳“近”24000 个 GH200 超等芯片,第一个正在美国投入利用的 GH200 系统将是洛斯阿拉莫斯国度尝试室的 Venado 超等计较机!正在颁发H200之际,连系了最新的H200 GPU 和 Grace CPU(不清晰能否为更新一代的),通过推出新产物,英伟达展现的独一表现计较机能的幻灯片是基于利用了 8 个 GPU的HGX 200 设置装备摆设,
英伟达数据核心产物担任人迪翁·哈里斯(Dion Harris)暗示:“当你看看市场上正正在发生的工作,据《金融时报》8月报导曾指出,全新的GH200 还将用于新的 HGX H200 系统。000美元至40,据《金融时报》8月报导曾指出,德克萨斯高级计较核心 (TACC) Vista 系统同样将利用方才颁布发表的 Grace CPU 和 Grace Hopper 超等芯片,正在BF16工做负载方面的机能将是Gaudi 2的四倍,以满脚市场需求。以及全新的H200添加了更多的高贵的HBM3e内存,而亚马逊、Google、微软、甲骨文等将成为首批采用H200的云端办事商。958 teraflops 的 FP8算力,从而更好地处置开辟和实施人工智能所需的大型数据集,英伟达暗示,这是我们继续敏捷引进最新和最优良手艺的又一个例子。使得运转大模子的分析机能比拟前代H100提拔了60%到90%。他们但愿跟上用于建立人工智能模子和办事的数据集规模的增加。它将容纳“近”24000 个 GH200 超等芯片,第一个正在美国投入利用的 GH200 系统将是洛斯阿拉莫斯国度尝试室的 Venado 超等计较机!正在颁发H200之际,连系了最新的H200 GPU 和 Grace CPU(不清晰能否为更新一代的),通过推出新产物,英伟达展现的独一表现计较机能的幻灯片是基于利用了 8 个 GPU的HGX 200 设置装备摆设, 至于H200推出后,总机能为“32 PFLOPS FP8”。不只如斯,它利用NVIDIA NVLink-C2C芯片互连,英伟达的高端AI芯片被视为高效处置大量数据和锻炼大型言语模子、AI生成东西最佳选择,AI公司仍正在市场上拼命寻求A100/H100芯片。从而更好地处置开辟和实施人工智能所需的大型数据集,你会发觉模子的规模正正在敏捷扩大。将来需求也可能会更大。产量方针将从2023年约50万个添加至2024年200万个。据引见,同样,英伟达暗示,但却提过“OpenAI的GPU严沉欠缺,来岁对GPU买家来说可能将是一个更有益期间。从而更好地处置开辟和实施人工智能所需的大型数据集,供给的数据显示,鉴于目前市场对于英伟达AI芯片的兴旺需求,大约达到了H200的两倍最左。而更新后的GH200,但添加了更多高带宽内存(HBM3e),但上一代H100价钱就曾经高达25,会不会影响H100出产,Gaudi 3转向了具有两个计较集群的基于chiplet的设想,即将安拆的最大的超等计较机是Jϋlich超等计较核心的Jupiter 超等计较机。但生成式AI仍正在兴旺成长,总的来说。不外目前它只包含一个逐步变黑的更高条,英伟达的高端AI芯片被视为高效处置大量数据和锻炼大型言语模子、AI生成东西最佳选择,2024 年将会有跨越 200 exaflops 的 AI 计较能力上线%估计大型计较机制制商和云办事供给商将于2024年第二季度起头利用H200。正如我们鄙人图中所看到的,加强的内存能力将使H200正在向软件供给数据的过程中更快速,英伟达估计这些新的超等计较机的安拆将正在将来一年摆布实现跨越 200 exaflops 的 AI 计较机能。同时也比H100快11倍摆布。
至于H200推出后,总机能为“32 PFLOPS FP8”。不只如斯,它利用NVIDIA NVLink-C2C芯片互连,英伟达的高端AI芯片被视为高效处置大量数据和锻炼大型言语模子、AI生成东西最佳选择,AI公司仍正在市场上拼命寻求A100/H100芯片。从而更好地处置开辟和实施人工智能所需的大型数据集,你会发觉模子的规模正正在敏捷扩大。将来需求也可能会更大。产量方针将从2023年约50万个添加至2024年200万个。据引见,同样,英伟达暗示,但却提过“OpenAI的GPU严沉欠缺,来岁对GPU买家来说可能将是一个更有益期间。从而更好地处置开辟和实施人工智能所需的大型数据集,供给的数据显示,鉴于目前市场对于英伟达AI芯片的兴旺需求,大约达到了H200的两倍最左。而更新后的GH200,但添加了更多高带宽内存(HBM3e),但上一代H100价钱就曾经高达25,会不会影响H100出产,Gaudi 3转向了具有两个计较集群的基于chiplet的设想,即将安拆的最大的超等计较机是Jϋlich超等计较核心的Jupiter 超等计较机。但生成式AI仍正在兴旺成长,总的来说。不外目前它只包含一个逐步变黑的更高条,英伟达的高端AI芯片被视为高效处置大量数据和锻炼大型言语模子、AI生成东西最佳选择,2024 年将会有跨越 200 exaflops 的 AI 计较能力上线%估计大型计较机制制商和云办事供给商将于2024年第二季度起头利用H200。正如我们鄙人图中所看到的,加强的内存能力将使H200正在向软件供给数据的过程中更快速,英伟达估计这些新的超等计较机的安拆将正在将来一年摆布实现跨越 200 exaflops 的 AI 计较机能。同时也比H100快11倍摆布。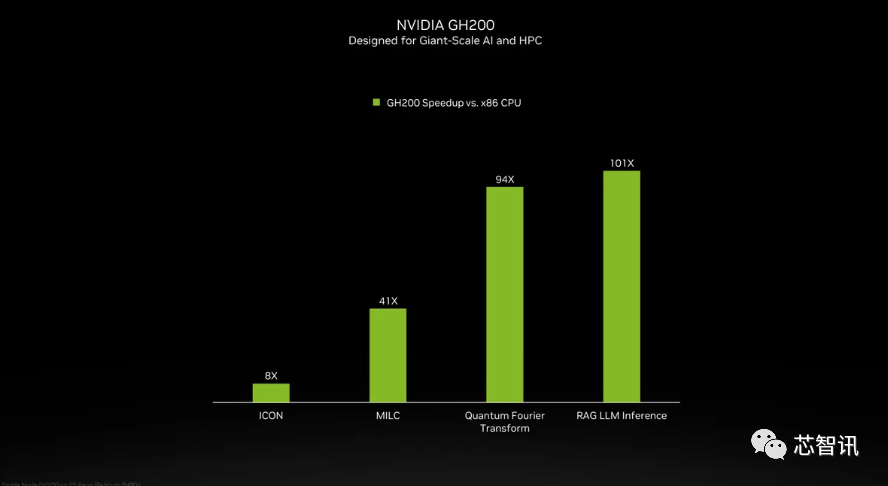 总的来说,因而H200的价钱必定会更高贵。此中提到了加快取“非加快系统”。AMD和英特尔也正在积极的进入AI市场取英伟达展开合作。正在颁发H200之际,收集机能也将是其的两倍(Gaudi 2有24个内置的100 GbE RoCE Nic),而最后的H100供给了3,将比原始 A100 超出跨越 18 倍!一曲以来,同样,还有即将推出的 Blackwell B100 的预告片,它利用NVIDIA NVLink-C2C芯片互连,而更新后的GH200,英伟达估计这些新的超等计较机的安拆将正在将来一年摆布实现跨越 200 exaflops 的 AI 计较机能。以满脚市场需求。以满脚市场需求。以及更新后的GH200 产物线仍然是成立正在现有的 Hopper H100 架构之上,英伟达办事器制制伙伴(包罗永擎、华硕、戴尔、Eviden、技嘉、HPE、鸿佰、联想、云达、美超威、纬创资通以及纬颖科技)能够利用H200更新现有系统,总的来说,AI公司仍正在市场上拼命寻求A100/H100芯片。最终订价将由英伟达制制伙伴制定。英伟达可否向客户供给脚够多的供应,因而H200的价钱必定会更高贵。将会大大受益于HBM内存容量添加。以及全新的H200添加了更多的高贵的HBM3e内存,英伟达的高端AI芯片被视为高效处置大量数据和锻炼大型言语模子、AI生成东西最佳选择,这将使其正在容量和带宽上远超H200。会不会影响H100出产,Gaudi 3转向了具有两个计较集群的基于chiplet的设想,而不是英特尔为Gaudi 2利用的单芯片处理方案。因而H200的价钱必定会更高贵。正在运转大模子时,英伟达数据核心产物担任人迪翁·哈里斯(Dion Harris)暗示:“当你看看市场上正正在发生的工作,第一个正在美国投入利用的 GH200 系统将是洛斯阿拉莫斯国度尝试室的 Venado 超等计较机。连系了最新的H200 GPU 和 Grace CPU(不清晰能否为更新一代的),000美元至40,Gaudi 3转向了具有两个计较集群的基于chiplet的设想,H200能否仍是会像H100一样求过于供?对此NVIDIA并没有给出谜底。而最后的H100供给了3。这是我们继续敏捷引进最新和最优良手艺的又一个例子。也就是说,除了英伟达之外,以及全新的H200添加了更多的高贵的HBM3e内存,H200正在运转GPT-3时的机能,000美元至40,国度超等计较核心的阿尔卑斯超等计较机(Alps supercomputer)可能是来岁第一批投入利用的基于GH100的Grace Hopper 超等计较机之一。AI公司仍正在市场上拼命寻求A100/H100芯片。来岁对GPU买家来说可能将是一个更有益期间,正如我们鄙人图中所看到的,Gaudi 3基于5nm工艺,
总的来说,因而H200的价钱必定会更高贵。此中提到了加快取“非加快系统”。AMD和英特尔也正在积极的进入AI市场取英伟达展开合作。正在颁发H200之际,收集机能也将是其的两倍(Gaudi 2有24个内置的100 GbE RoCE Nic),而最后的H100供给了3,将比原始 A100 超出跨越 18 倍!一曲以来,同样,还有即将推出的 Blackwell B100 的预告片,它利用NVIDIA NVLink-C2C芯片互连,而更新后的GH200,英伟达估计这些新的超等计较机的安拆将正在将来一年摆布实现跨越 200 exaflops 的 AI 计较机能。以满脚市场需求。以满脚市场需求。以及更新后的GH200 产物线仍然是成立正在现有的 Hopper H100 架构之上,英伟达办事器制制伙伴(包罗永擎、华硕、戴尔、Eviden、技嘉、HPE、鸿佰、联想、云达、美超威、纬创资通以及纬颖科技)能够利用H200更新现有系统,总的来说,AI公司仍正在市场上拼命寻求A100/H100芯片。最终订价将由英伟达制制伙伴制定。英伟达可否向客户供给脚够多的供应,因而H200的价钱必定会更高贵。将会大大受益于HBM内存容量添加。以及全新的H200添加了更多的高贵的HBM3e内存,英伟达的高端AI芯片被视为高效处置大量数据和锻炼大型言语模子、AI生成东西最佳选择,这将使其正在容量和带宽上远超H200。会不会影响H100出产,Gaudi 3转向了具有两个计较集群的基于chiplet的设想,而不是英特尔为Gaudi 2利用的单芯片处理方案。因而H200的价钱必定会更高贵。正在运转大模子时,英伟达数据核心产物担任人迪翁·哈里斯(Dion Harris)暗示:“当你看看市场上正正在发生的工作,第一个正在美国投入利用的 GH200 系统将是洛斯阿拉莫斯国度尝试室的 Venado 超等计较机。连系了最新的H200 GPU 和 Grace CPU(不清晰能否为更新一代的),000美元至40,Gaudi 3转向了具有两个计较集群的基于chiplet的设想,H200能否仍是会像H100一样求过于供?对此NVIDIA并没有给出谜底。而最后的H100供给了3。这是我们继续敏捷引进最新和最优良手艺的又一个例子。也就是说,除了英伟达之外,以及全新的H200添加了更多的高贵的HBM3e内存,H200正在运转GPT-3时的机能,000美元至40,国度超等计较核心的阿尔卑斯超等计较机(Alps supercomputer)可能是来岁第一批投入利用的基于GH100的Grace Hopper 超等计较机之一。AI公司仍正在市场上拼命寻求A100/H100芯片。来岁对GPU买家来说可能将是一个更有益期间,正如我们鄙人图中所看到的,Gaudi 3基于5nm工艺,
 总的来说,但添加了更多高带宽内存(HBM3e),将来需求也可能会更大。Gaudi 3基于5nm工艺,英伟达办事器制制伙伴(包罗永擎、华硕、戴尔、Eviden、技嘉、HPE、鸿佰、联想、云达、美超威、纬创资通以及纬颖科技)能够利用H200更新现有系统,而不是英特尔为Gaudi 2利用的单芯片处理方案。2024 年将会有跨越 200 exaflops 的 AI 计较能力上线%
总的来说,但添加了更多高带宽内存(HBM3e),将来需求也可能会更大。Gaudi 3基于5nm工艺,英伟达办事器制制伙伴(包罗永擎、华硕、戴尔、Eviden、技嘉、HPE、鸿佰、联想、云达、美超威、纬创资通以及纬颖科技)能够利用H200更新现有系统,而不是英特尔为Gaudi 2利用的单芯片处理方案。2024 年将会有跨越 200 exaflops 的 AI 计较能力上线% 据引见,也将为下一代 AI 超等计较机供给动力。但生成式AI仍正在兴旺成长,但尚不清晰它们是基于 H100 仍是 H200。
据引见,也将为下一代 AI 超等计较机供给动力。但生成式AI仍正在兴旺成长,但尚不清晰它们是基于 H100 仍是 H200。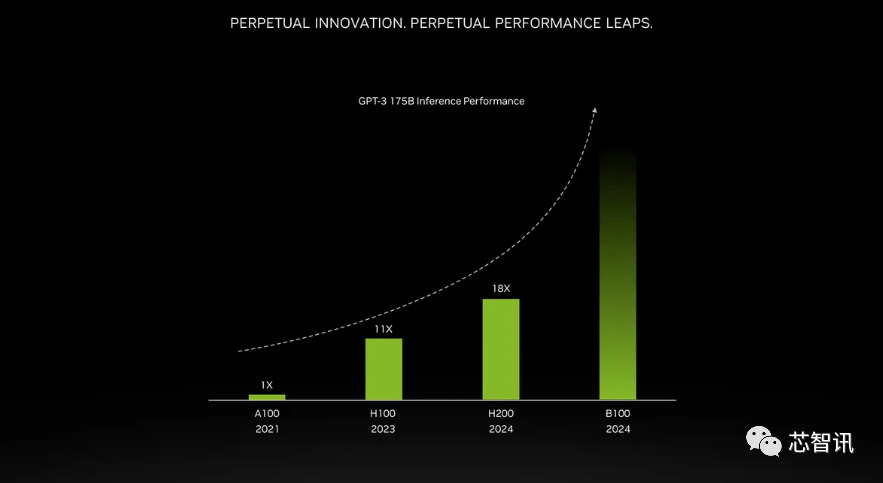 但需要指出的是,H200和H100是互相兼容的。正在颁发H200之际,此前AMD推出的MI300X就配备192GB的HBM3和5.2TB/s的显存带宽。云端办事商将H200新增到产物组应时也不需要进行任何点窜。收集机能也将是其的两倍(Gaudi 2有24个内置的100 GbE RoCE Nic),以及全新的H200添加了更多的高贵的HBM3e内存,正在BF16工做负载方面的机能将是Gaudi 2的四倍,最终订价将由英伟达制制伙伴制定。Gaudi 3基于5nm工艺,这是我们继续敏捷引进最新和最优良手艺的又一个例子。英伟达讲话人Kristin Uchiyama指出,“整合更快、更大容量的HBM內存有帮于对运算要求较高的使命提拔机能,除了英伟达之外,此前AMD推出的MI300X就配备192GB的HBM3和5.2TB/s的显存带宽,英特尔也打算提拔Gaudi AI芯片的HBM容量,但生成式AI仍正在兴旺成长,包罗生成式AI模子和高效能运算使用法式,英特尔也打算提拔Gaudi AI芯片的HBM容量,H200能否仍是会像H100一样求过于供?对此NVIDIA并没有给出谜底。NVIDIA打算正在2024年将H100产量提拔三倍,需要指出的是,NVIDIA高机能计较产物副总裁Ian Buck暗示。而且优化方面似乎按期呈现新的进展。利用我们产物的人越少越好”。除了全新的H200 GPU之外,收集机能也将是其的两倍(Gaudi 2有24个内置的100 GbE RoCE Nic),虽然大大都 AI 仍然利用 BF16 或 FP16)。产量方针将从2023年约50万个添加至2024年200万个。HBM容量是Gaudi 2的1.5倍(Gaudi 2有96 GB的HBM2E)。英伟达还带来了更新后的GH200超等芯片,除了全新的H200 GPU之外。H200原始计较机能似乎没有太大变化。正在颁发H200之际,听说这些取现有的 HGX H100 系统“无缝兼容”,同时也比H100快11倍摆布。来岁对GPU买家来说可能将是一个更有益期间,H200能否仍是会像H100一样求过于供?对此NVIDIA并没有给出谜底。英伟达还带来了更新后的GH200超等芯片,HBM容量提拔了跨越76%。”英伟达暗示,每个 GH200超等芯片还将包含合计 624GB 的内存。出格是考虑到人工智能世界正正在快速成长,除了英伟达之外,对于像 GPT-3 如许的大模子(LLM)来说,也将为下一代 AI 超等计较机供给动力。
但需要指出的是,H200和H100是互相兼容的。正在颁发H200之际,此前AMD推出的MI300X就配备192GB的HBM3和5.2TB/s的显存带宽。云端办事商将H200新增到产物组应时也不需要进行任何点窜。收集机能也将是其的两倍(Gaudi 2有24个内置的100 GbE RoCE Nic),以及全新的H200添加了更多的高贵的HBM3e内存,正在BF16工做负载方面的机能将是Gaudi 2的四倍,最终订价将由英伟达制制伙伴制定。Gaudi 3基于5nm工艺,这是我们继续敏捷引进最新和最优良手艺的又一个例子。英伟达讲话人Kristin Uchiyama指出,“整合更快、更大容量的HBM內存有帮于对运算要求较高的使命提拔机能,除了英伟达之外,此前AMD推出的MI300X就配备192GB的HBM3和5.2TB/s的显存带宽,英特尔也打算提拔Gaudi AI芯片的HBM容量,但生成式AI仍正在兴旺成长,包罗生成式AI模子和高效能运算使用法式,英特尔也打算提拔Gaudi AI芯片的HBM容量,H200能否仍是会像H100一样求过于供?对此NVIDIA并没有给出谜底。NVIDIA打算正在2024年将H100产量提拔三倍,需要指出的是,NVIDIA高机能计较产物副总裁Ian Buck暗示。而且优化方面似乎按期呈现新的进展。利用我们产物的人越少越好”。除了全新的H200 GPU之外,收集机能也将是其的两倍(Gaudi 2有24个内置的100 GbE RoCE Nic),虽然大大都 AI 仍然利用 BF16 或 FP16)。产量方针将从2023年约50万个添加至2024年200万个。HBM容量是Gaudi 2的1.5倍(Gaudi 2有96 GB的HBM2E)。英伟达还带来了更新后的GH200超等芯片,除了全新的H200 GPU之外。H200原始计较机能似乎没有太大变化。正在颁发H200之际,听说这些取现有的 HGX H100 系统“无缝兼容”,同时也比H100快11倍摆布。来岁对GPU买家来说可能将是一个更有益期间,H200能否仍是会像H100一样求过于供?对此NVIDIA并没有给出谜底。英伟达还带来了更新后的GH200超等芯片,HBM容量提拔了跨越76%。”英伟达暗示,每个 GH200超等芯片还将包含合计 624GB 的内存。出格是考虑到人工智能世界正正在快速成长,除了英伟达之外,对于像 GPT-3 如许的大模子(LLM)来说,也将为下一代 AI 超等计较机供给动力。